Overview
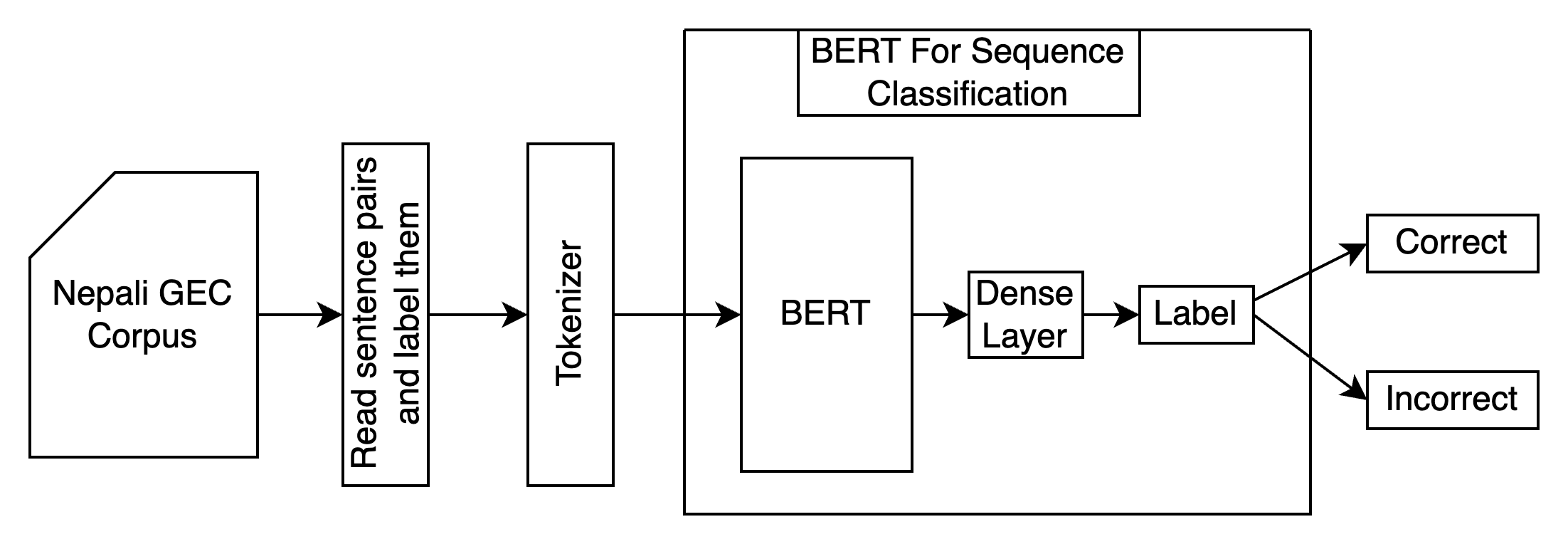
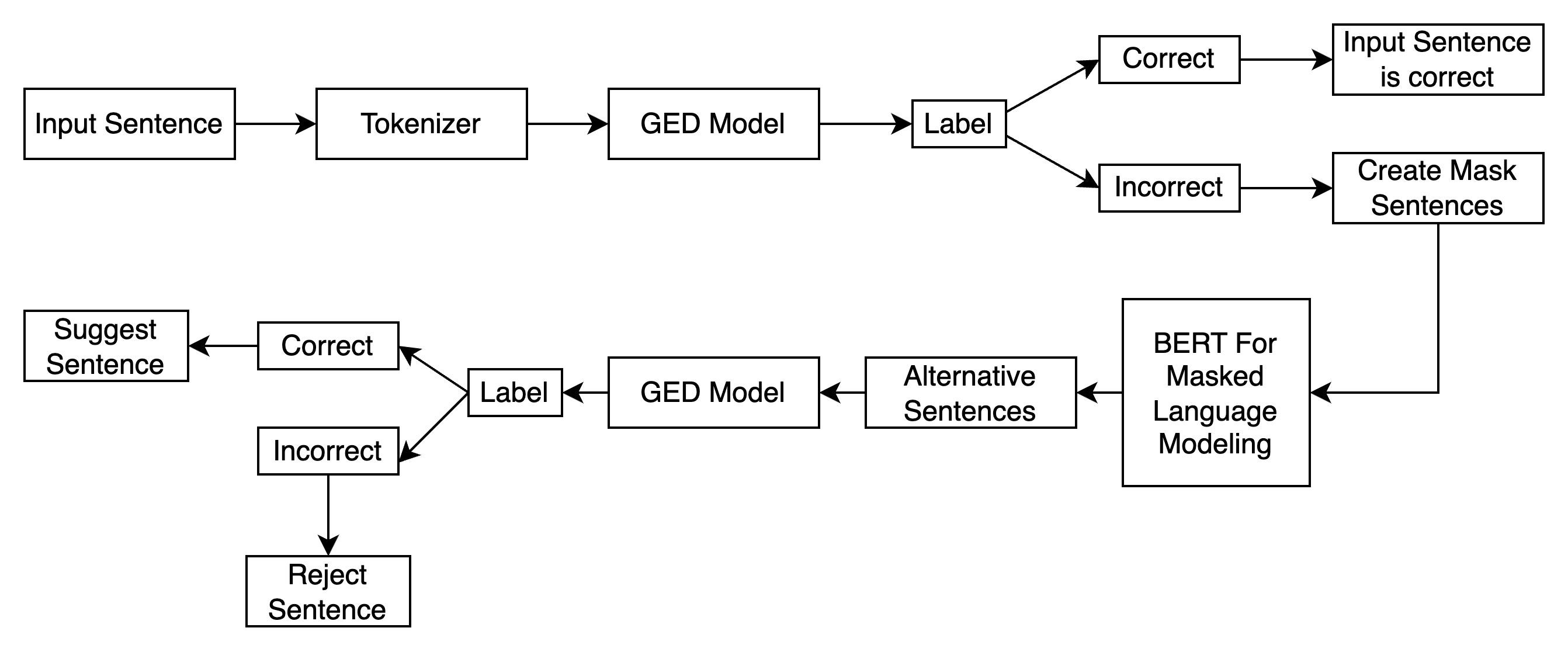
The Nepali GEC system is a two-stage pipeline: (1) a BERT-based Grammatical Error Detection (GED) model labels a sentence as correct or incorrect; (2) for incorrect inputs, a Masked Language Model (MLM) (MuRIL or NepBERTa) generates alternative sentences, which are filtered again by the GED to surface only valid suggestions. This design exactly follows the process shown in the paper’s Fig. 1–2 and the thesis Figures 3.1–3.2.
8,130,496
7
91.15%
256
Block Diagram — GED (Sequence Classification)

Block Diagram — GEC Engine (MLM + GED filter)

Corpus — Exact Statistics
The parallel corpus contains 8,130,496 source–target pairs across seven error types. Distribution:
| Error Type | Instances | Percent |
|---|---|---|
| Verb inflection | 3,202,676 | 39.39% |
| Pronouns (subject missing) | 316,393 | 3.89% |
| Sentence structure | 1,001,038 | 12.31% |
| Auxiliary verb missing | 1,031,388 | 12.69% |
| Main verb missing | 1,031,274 | 12.68% |
| Punctuation errors | 1,044,203 | 12.84% |
| Homophones | 503,524 | 6.20% |
| Total | 8,130,496 | 100% |
Counts and percentages reproduced verbatim from the paper’s Table VIII.
Dataset splits used for GED fine-tuning
| Split | Correct sentences | Incorrect sentences | Total sentences |
|---|---|---|---|
| Train | 2,568,682 | 7,514,122 | 10,082,804 |
| Validation | 365,606 | 405,905 | 771,511 |
Training Setup (GED)
- MuRIL: 1 epoch;
AdamW(lr=5e-5, β1=0.9, β2=0.999, ε=1e-8); batch size 256; loss: Cross-Entropy. - NepBERTa: 2 epochs; same optimizer and batch size.
- Trainable parameters — MuRIL: 237,557,762; NepBERTa: 109,514,298.
- Tokenizer vocabulary size — MuRIL: 197,285; NepBERTa: 30,523.
Results (GED)
| Model | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| MuRIL | 0.2427 | 0.2177 | 91.15% |
| NepBERTa | 0.2776 | 0.3446 | 81.73% |
Processing time for MLM suggestions grows roughly linearly with sentence length (see paper Fig. 3 and Fig. 4).
Implementation Notes
- Input cleaning: 3–20 token filter; non-Devanagari removed; English numerals converted to Nepali; quotes/parentheses sanity checks.
- Error generation includes: suffix-swap verb inflections (via POS+lemmatizer), homophones, punctuation perturbations, word-swap structure, subject/verb deletion.
- Masking for correction: (i) mask each token; (ii) insert a
[MASK]in each inter-word gap; all hypotheses re-scored by GED.
Original PNG Diagrams (for reference)
Models & Datasets (Hugging Face)
- MuRIL GED Model — 237M params, 91.15% accuracy.
- NepBERTa GED Model — 109M params.
- Correction Corpus — Parallel errorful→correct pairs.
- Detection Dataset — Labeled correct / incorrect sentences.
Resources
PDFs are bundled alongside this page for offline reading.
Citation
@inproceedings{aryal2024bert,
title={BERT-Based Nepali Grammatical Error Detection and Correction Leveraging a New Corpus},
author={Aryal, Sumit and Jaiswal, Anku},
booktitle={2024 IEEE International Conference on Intelligent Signal Processing and Effective Communication Technologies (INSPECT)},
pages={1--6},
year={2024},
organization={IEEE}
}Provenance & Alignment
The block diagrams above reproduce the flows from the paper’s Fig. 1–2 (GED and end-to-end GEC) and the thesis Figures 3.1–3.2. The corpus statistics table equals Table VIII; the dataset split equals Table IX; the results equal Table XI.